I have a knack for solving TypeScript riddles posed by my coworkers. It’s my “stupid human trick”.
A coworker posed this today:
is there a way to take something like
type Foo = [{name: 'one', value: boolean}, {name: 'two': value: number}]And turn it into
type Bar = {one: boolean, two: number}
I like to challenge myself to respond to these types of questions with a link to https://href.li/?https://www.typescriptlang.org/play containing a working solution.
In this case I responded 12 minutes later with this solution. (I’m not sure exactly when I saw the message, though. So it was definitely under 12 minutes. I saw it when I came back from lunch. Yes, I’m trying to brag here, but this is really my one differentiating skill so I’ve got to milk it. Please forgive me.)
type Foo = [
{name: 'one', value: boolean},
{name: 'two', value: number}
]
type NameIndexedTypes<T, Result extends Record<never, never> = {}> =
T extends [infer Head, ...infer Rest]
? Head extends { value: infer Value, name: infer Name extends string}
? NameIndexedTypes<Rest, Record<Name, Value> & Result>
: never
: Result
type Bar = NameIndexedTypes<Foo>;
const good: Bar = {
one: false,
two: 2
}
const bad: Bar = {
one: 'one',
two: 'two'
}
Let’s break this down.
The source type Foo is a tuple type. It appears as though the expectation is that each member of the tuple will have a Record type with a name that extends from a string and a value of anything else.
Given these constraints let’s dive into a solution.
Reduce a Tuple
When you take something that is an enumerable (in this case a tuple) and you want to transform it into something else entirely (in this case a Record<?, ?>, it’s time to perform a reduce.
In functional programming, reduce is iterating over a collection and for each item in the collection, aggregating it into something else.
An equivalent concept in JavaScript is Array.prototype.reduce().
TypeScript does nat have a built-in reduce operation. But the pattern can be reproduced.
Reducing over the tuple and returning a Record requires a type with two generics. One for the tuple and one for the transformed Record that gets aggregated and returned.
type IndexedByName<
T,
Result extends Record<never, never> = {}
>;If you’re unfamiliar with generics or they seem indecipherable, in TypeScript’s world this is really no different than defining a function that takes in two arguments.
In this case the first argument is named T. This will expect the tuple.
The second argument is Result. This constrains the Result to extend Record<never, never> and assigns a default to {}. (note: a better default could be Record<never, never> because {} is pretty much the same as any).
Why Record<never, never>? Usage of any is banned in this codebase. (Using an any in the extends clause isn’t really a safety risk, but those are the rules).
The domain (or key) type of a Record is constrained to string | number | symbol. This means unknown won’t work which is usually the safer solution to using any. Record<never, never> here indicates to the type system that it needs to be a Record, but the domain and value types are not specified.
Since the default of {} is provided, the type can be used without specifying the initial Result:
type MyResult = IndexedByName<MyTuple>;Starting the Reduce
The first thing to do is extract the first item (the “head”) from the tuple. In TypeScript this is done with a conditional type.
T extends [infer Head, ...infer Rest]
? // do something with Head and
: // the else caseIn TypeScript you’re writing ternary statements. (The place I used to work banned ternaries because the aren’t readable. I’m a big fan of ternaries, so this always made me sad.)
In the true case of the ternary (the code after the ?), Head and Rest will be available type aliases. Rest has — well — the rest of the tuple while Head is now the member of tuple that was the first item.
Now it’s time to handle the true branch.
A Record with one key/value pair
Given the type Foo from the original question, in the first iteration over the tuple the Head will be aliased to
type Head = { name: 'one', value: boolean };To solve the next stage of this problem this map type with keys of name and value need to become a Record type with a key of one and a value of boolean.
Time for another conditional type.
// The first true branch of the first ternary
Head extends { name: infer Name extends string, value: infer Value }
? // next true branch
: // next false branchThis now checks if Head extends the expected shape and captures the two types into to aliases. Using the first member of Foo as the example, the aliases are now:
Namealiased to'one'Valuealiased toboolean
Usually when defining a type with explicit members an interface or type alias is used with an explicit key name:
// interface example
interface Whatever {
one: boolean;
}
// type alias example
type Whatever {
one: boolean;
}This can also be define with a Record type with a string subtype:
type Whatever = Record<'one', boolean>;So if you wanted to build up a bunch of key/value pairs and merge them into a single type they can be intersected (&) together.
The usual way:
type Whatever {
one: boolean;
two: 'a' | 'b' | 'c';
}The intersection way:
type Whatever =
Record<'one', boolean>
& Record<'two', 'a' | 'b' | 'c'>;So never define a mapped type alias this way. Your coworkers will hate you. But if you need to reduce a tuple and merge the results into a single type, this is the tool you have to reach for.
So back to the solution. Now that Name and Value have been infered, Record<Name, Value> can be intersected with the current Result to produce a merged Record type.
Result & Record<Name, Value>Tail call recursion
And thus we reach the meat of the solution.
// The second ternary after infer Name/Value
? IndexedByName<Rest, Result & Record<Name, Value>>All in a single line:
- Recursively call the the
IndexedByNametype - Use
Restwhich contains the tail of thetupletype - Intersect (
&)- The carried
Resulttype (the second generic input toIndexedByName - And the single key/value pair
Record<Name, Value>described above
- The carried
In the case of type Foo this means the it’s going to make a recursive call that looks like this:
IndexedByName<
[{ name: 'two', value: boolean}],
Record<'one', number>
>Another thing to point out here is that the conditional type requires Name extends string.
A Record‘s key type has to be a type of string | number | symbol so it’s being constrained here so it can be used with Record. Using infer inside the extends statement was introduced in TypeScript 4.8. Prior to 4.8 an extra conditional type would be required.
In the original ask I assumed that members of Foo will have a string subtype for name but a more liberal solution could use extends number | string | symbol which means Foo could have a member of:
type MemberWithNumericalName = {
name: 123;
value: string;
};Exiting the recursion
So far the example handles both true branches in the two conditional types used in this solution.
The first ternary will branch into the “else” portion if T cannot infer a Head type which means T is now an empty tuple ([]). This means the recursion is done, so for the false branch of the first ternary, the Result alias can be returned as is:
: Result;In the second nested ternary, the solution exits with never. This branch is reached if the member in the tuple does not match an expected type of:
type { name: string, value: unknown };With the false branches of the ternary the solution is complete.
Extra credit
I wasn’t completely happy with the solution. The inferred type that comes out of IndexedByName isn’t the most readable:
An example with four entries in the incoming tuple will produce an inferred type with the intersecting Record types:

This tries to communicate that the type needs to have valid key/value pairs for 'four', 'three', 'two', 'one' keys. But the type you’d expect to use would be something more like:
type Better {
one: boolean;
two: number;
three: boolean;
four: boolean;
}TypeScript can be forced into using this type using a mapped type on Result:
: {[K in keyof Result]: Result[K]}The intersection of Record types are now merged into a single type alias:
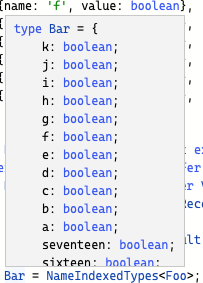
Tests
When introducing types like this into the codebase I like to unit test my types.
How do you unit test types? @ts-expect-error.
This codebase uses jest. In this case there really is no need for a runtime test, but using a stubbed out one can also be used for some type assertions.
# IndexedByName.test.ts
describe('IndexedByName', () => {
type Foo = [
{ name: 'one', value: boolean },
{ name: 'two': value: number },
];
type Bar = IndexedByName<Foo>;
// @ts-expect-error BadRecord can't be a string
type BadRecord: Bar = 'hi';
type BadKey = {
// @ts-expect-error one must be a boolean
one: 'hi';
two: 1;
}
// @ts-expect-error missing key of one
type MissingKey = {
two: 1;
}
it('works', () => {
const value: Bar = {
one: true,
two: 2
}
expect(value.one).toBe(true);
});
});If the IndexedByName type were to stop working the @ts-expect-error statements would fail tsc.
The only thing worse than no types are types that give you a false sense of safety.