
Humanity will keep trying to build grander cathedrals, but there’s no contest, nature already built the grandest.
Humanity will keep trying to build grander cathedrals, but there’s no contest, nature already built the grandest.

If you ever ski at Mt. Baker Ski Resort you’re always treated to a view of Shuksan as you ride up Chair 8.
This summer, as I summited Ruth Mountain I was blown away by Nooksack Cirque. What an unexpected and stunning sight of a side of Shuksan you’d never know was there.


I have a knack for solving TypeScript riddles posed by my coworkers. It’s my “stupid human trick”.
A coworker posed this today:
is there a way to take something like
type Foo = [{name: 'one', value: boolean}, {name: 'two': value: number}]And turn it into
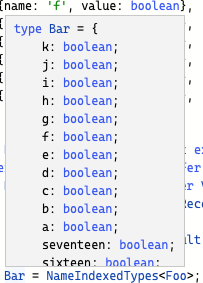
type Bar = {one: boolean, two: number}
I like to challenge myself to respond to these types of questions with a link to https://href.li/?https://www.typescriptlang.org/play containing a working solution.
In this case I responded 12 minutes later with this solution. (I’m not sure exactly when I saw the message, though. So it was definitely under 12 minutes. I saw it when I came back from lunch. Yes, I’m trying to brag here, but this is really my one differentiating skill so I’ve got to milk it. Please forgive me.)
type Foo = [
{name: 'one', value: boolean},
{name: 'two', value: number}
]
type NameIndexedTypes<T, Result extends Record<never, never> = {}> =
T extends [infer Head, ...infer Rest]
? Head extends { value: infer Value, name: infer Name extends string}
? NameIndexedTypes<Rest, Record<Name, Value> & Result>
: never
: Result
type Bar = NameIndexedTypes<Foo>;
const good: Bar = {
one: false,
two: 2
}
const bad: Bar = {
one: 'one',
two: 'two'
}
Let’s break this down.
The source type Foo is a tuple type. It appears as though the expectation is that each member of the tuple will have a Record type with a name that extends from a string and a value of anything else.
Given these constraints let’s dive into a solution.
When you take something that is an enumerable (in this case a tuple) and you want to transform it into something else entirely (in this case a Record<?, ?>, it’s time to perform a reduce.
In functional programming, reduce is iterating over a collection and for each item in the collection, aggregating it into something else.
An equivalent concept in JavaScript is Array.prototype.reduce().
TypeScript does nat have a built-in reduce operation. But the pattern can be reproduced.
Reducing over the tuple and returning a Record requires a type with two generics. One for the tuple and one for the transformed Record that gets aggregated and returned.
type IndexedByName<
T,
Result extends Record<never, never> = {}
>;If you’re unfamiliar with generics or they seem indecipherable, in TypeScript’s world this is really no different than defining a function that takes in two arguments.
In this case the first argument is named T. This will expect the tuple.
The second argument is Result. This constrains the Result to extend Record<never, never> and assigns a default to {}. (note: a better default could be Record<never, never> because {} is pretty much the same as any).
Why Record<never, never>? Usage of any is banned in this codebase. (Using an any in the extends clause isn’t really a safety risk, but those are the rules).
The domain (or key) type of a Record is constrained to string | number | symbol. This means unknown won’t work which is usually the safer solution to using any. Record<never, never> here indicates to the type system that it needs to be a Record, but the domain and value types are not specified.
Since the default of {} is provided, the type can be used without specifying the initial Result:
type MyResult = IndexedByName<MyTuple>;The first thing to do is extract the first item (the “head”) from the tuple. In TypeScript this is done with a conditional type.
T extends [infer Head, ...infer Rest]
? // do something with Head and
: // the else caseIn TypeScript you’re writing ternary statements. (The place I used to work banned ternaries because the aren’t readable. I’m a big fan of ternaries, so this always made me sad.)
In the true case of the ternary (the code after the ?), Head and Rest will be available type aliases. Rest has — well — the rest of the tuple while Head is now the member of tuple that was the first item.
Now it’s time to handle the true branch.
Given the type Foo from the original question, in the first iteration over the tuple the Head will be aliased to
type Head = { name: 'one', value: boolean };To solve the next stage of this problem this map type with keys of name and value need to become a Record type with a key of one and a value of boolean.
Time for another conditional type.
// The first true branch of the first ternary
Head extends { name: infer Name extends string, value: infer Value }
? // next true branch
: // next false branchThis now checks if Head extends the expected shape and captures the two types into to aliases. Using the first member of Foo as the example, the aliases are now:
Name aliased to 'one'Value aliased to booleanUsually when defining a type with explicit members an interface or type alias is used with an explicit key name:
// interface example
interface Whatever {
one: boolean;
}
// type alias example
type Whatever {
one: boolean;
}This can also be define with a Record type with a string subtype:
type Whatever = Record<'one', boolean>;So if you wanted to build up a bunch of key/value pairs and merge them into a single type they can be intersected (&) together.
The usual way:
type Whatever {
one: boolean;
two: 'a' | 'b' | 'c';
}The intersection way:
type Whatever =
Record<'one', boolean>
& Record<'two', 'a' | 'b' | 'c'>;So never define a mapped type alias this way. Your coworkers will hate you. But if you need to reduce a tuple and merge the results into a single type, this is the tool you have to reach for.
So back to the solution. Now that Name and Value have been infered, Record<Name, Value> can be intersected with the current Result to produce a merged Record type.
Result & Record<Name, Value>And thus we reach the meat of the solution.
// The second ternary after infer Name/Value
? IndexedByName<Rest, Result & Record<Name, Value>>All in a single line:
IndexedByName typeRest which contains the tail of the tuple type&)
Result type (the second generic input to IndexedByNameRecord<Name, Value> described aboveIn the case of type Foo this means the it’s going to make a recursive call that looks like this:
IndexedByName<
[{ name: 'two', value: boolean}],
Record<'one', number>
>Another thing to point out here is that the conditional type requires Name extends string.
A Record‘s key type has to be a type of string | number | symbol so it’s being constrained here so it can be used with Record. Using infer inside the extends statement was introduced in TypeScript 4.8. Prior to 4.8 an extra conditional type would be required.
In the original ask I assumed that members of Foo will have a string subtype for name but a more liberal solution could use extends number | string | symbol which means Foo could have a member of:
type MemberWithNumericalName = {
name: 123;
value: string;
};So far the example handles both true branches in the two conditional types used in this solution.
The first ternary will branch into the “else” portion if T cannot infer a Head type which means T is now an empty tuple ([]). This means the recursion is done, so for the false branch of the first ternary, the Result alias can be returned as is:
: Result;In the second nested ternary, the solution exits with never. This branch is reached if the member in the tuple does not match an expected type of:
type { name: string, value: unknown };With the false branches of the ternary the solution is complete.
I wasn’t completely happy with the solution. The inferred type that comes out of IndexedByName isn’t the most readable:
An example with four entries in the incoming tuple will produce an inferred type with the intersecting Record types:

This tries to communicate that the type needs to have valid key/value pairs for 'four', 'three', 'two', 'one' keys. But the type you’d expect to use would be something more like:
type Better {
one: boolean;
two: number;
three: boolean;
four: boolean;
}TypeScript can be forced into using this type using a mapped type on Result:
: {[K in keyof Result]: Result[K]}The intersection of Record types are now merged into a single type alias:
When introducing types like this into the codebase I like to unit test my types.
How do you unit test types? @ts-expect-error.
This codebase uses jest. In this case there really is no need for a runtime test, but using a stubbed out one can also be used for some type assertions.
# IndexedByName.test.ts
describe('IndexedByName', () => {
type Foo = [
{ name: 'one', value: boolean },
{ name: 'two': value: number },
];
type Bar = IndexedByName<Foo>;
// @ts-expect-error BadRecord can't be a string
type BadRecord: Bar = 'hi';
type BadKey = {
// @ts-expect-error one must be a boolean
one: 'hi';
two: 1;
}
// @ts-expect-error missing key of one
type MissingKey = {
two: 1;
}
it('works', () => {
const value: Bar = {
one: true,
two: 2
}
expect(value.one).toBe(true);
});
});If the IndexedByName type were to stop working the @ts-expect-error statements would fail tsc.
The only thing worse than no types are types that give you a false sense of safety.
I don’t think Elon is going to ruin Twitter.
The number of “RPC calls” is incredibly low on the list of things Twitter needs to fix to make more money.
The fact that it’s still running mostly fine speaks volumes to the engineers who have set it up.
Going with a metaphor, Elon just bought one of the most complex Formula 1 teams and has thrown out most of the people who know how to maintain the car.
Sure it performs great now. But with the FIFA World Cup looming let’s hope they don’t run into any issues cause the team that knows how to fix the one-of-a-kind gearbox is no longer available to you.
And everyone knows Calacanis has no idea how to drive.
If you’re really cool like me and own a decade old Dodge Grand Caravan you may find that the Totally Integrated Power Module (TIPM) will start failing.
In common cases (like mine) it will stop activating the fuel pump relay. This means your car will turn over but not start. This is not a great feature but does potentially help with the climate change crisis.
Fortunately for me I have a mechanic just down the street. I’d like to not tow this beast. To diagnose all of this the internet mechanics mention opening your TIPM and hot-wiring the fuel relay circuit. I took at the relay’s fuse and used a multimeter. No voltage. Spot checked some others and was reading the expected volts.
I shoved a jumper wire from my battery-wired cigarette port fuse (not the key activated one) over to the fuel pump relay fuse and heard what sounded like an electric motor activate from beneath the car.
I turned the ignition and the car started right up. Off to the mechanic.
I explained my morning’s adventures to the mechanic. He looked skeptically at my patch wire and said he’d run a test to diagnose things. Could be the TIPM, maybe just the fuel pump.
We both knew it was the TIPM. Turns out it was the TIPM. Shocker.
The fix: new TIPM. The problem: since these things fail so ofter and they’re year/make/model specific and there’s a worldwide computer chip shortage I get a refurbed one. Oh yeah, and it’s going to take a week to ship it.
Turns out no car for a week is fine. Thanks to COVID most necessities are all delivered now.
After some delays and fakeouts from TIPM dealers I got the call that the van was ready to go.
Walked up to the shop and it started right up. Settled the bill (ouch) and brought it home.
Next day the right turn indicator started flipping out “front right turn signal out”. Guess I get to make a stop at the auto supply joint. Looked up the bulb number but before making a purchase decided to physically check all the lights first. The front right fog light has been out for forever so I might as well fix that while I’m at it.
I activate the left turn signal: the left fog light starts flashing. What?
I activate the right turn signal: no lights flashing. Ok, expected.
I push the fog light button: bot turn signals turn on. What?
Quick call to the mechanic to describe the situation. Basically got the “wasn’t my fault” spiel which is fine, wasn’t casting blame just trying to problem-solve here.
There’s a lot of downtime at kid’s baseball games so between innings I start asking the internet what it thinks of all of this. Eventually I put in the correct series of search terms and land on someone having the same problem. I searched the document number in the images: “k6855837”.
It lands me on a YouTube video that take me step-by-step through the process of performing this fix.
Apparently my new-to-me TIPM has a firmware update that changed the behavior of some circuits. Just gotta flip some wires. Since it turned into a car maintenance day I took the opportunity to pick up some new H11 headlight sockets and wire them in since Dodge seems to use janky wiring that melts every few years.
And hooray, a car that starts with correctly functioning lights.
This is my last American car I swear.
Search terms:
Not a complete list but these have not changed, even when being forced into environments that were actively hostile against me (WordPress PHP/JS code style is hideous).
I’ve been around a little while now so I’m instilling this wisdom to you.
The guaranteed way to become a 10x developer:
Hire ten developers whose mean productivity matches yours.
In the day job I recently recommended using Ramda to help clean up the readability of our UI code.
Ramda is a collection of pure functions designed to fit together using functional programming patterns.
We had a piece of TypeScript code landing that processed some data and rendered a React component.
const filteredLabels =
data.community.labels.filter((label) => {
if (label.type === LabelType.AutoLabel &&
(isGroupPage === true ?
['system_a', 'special'] :
['system_a']
).includes(label.name)
) {
return false;
}
if (label.type === LabelType.UserDefined &&
label.stats.timesUsed === 0) {
return false;
}
return true;
});
filteredLabels.sort((labelA, labelB) => {
if (labelA.type === LabelType.AutoLabel) {
if (labelB.type === LabelType.UserDefined) {
return -1;
}
return labelA.name.toLowerCase() < labelB.name.toLowerCase() ? -1 : 1;
}
if (labelB.type === LabelType.AutoLabel) {
return 1;
}
return labelA.name.toLowerCase() < labelB.name.toLowerCase() ? -1 : 1;
});
return filterdLabels.map((label) => <>{/* React UI */}</>Three distinct things are happening here:
data.community.labels.filter(/* ... */) is removing certain Label instances from the list.filteredLabels.sort(/* ... */) is sorting the filtered items first by their .type then by their .name (case-insensitive)filteredLabels.map(/* ... */) is turning the list of Label instances into a JSX.Element.The hardest part for me to decipher as a reader of the code was step two: given two labels what was the intended sort order?
After spending a few moments internalizing those if statements I came to the conclusion the two properties being used for comparison were label.type and label.name.
A label of .type === LabelType.AutoLabel should appear before a label of .type === LabelType.UserDefined.
Labels with the same .type should then be sorted by their .name case-insensitively.
sortWithThe problem I was encountering with this bit of code is that my human brain works this way:
Given a list of Labels:
- Sort them by their .type with .AutoLabel preceding .UserDefined
- Sort labels of the some .type by their .name case-insensitivelyRamda’s sortWith gives us an API that sounds similar in theory:
Sorts a list according to a list of comparators.
A “comparator” is typed with (a, a) => Number. My list of comparators will be one for the label.type and one for the label.name.
import { sortWith } from 'ramda';
const sortLabels = sortWith<Label>([
// 1. compare label types
// 2. compare label names
]);A comparator‘s return value here is a bit ambiguous declaring Number in the documentation. But their code example for sortWith points to some more handy functions: ascend and descend.
Here’s the description for ascend:
Makes an ascending comparator function out of a function that returns a value that can be compared with
<and>.
To sort by label.type I need to map the LabelType to value that will sort .AutoLabel to precede .UserDefined:
const sortLabels = sortWith<Label>([
ascend((label) => label.type === LabelType.AutoLabel ? -1 : 1,
// 2. compare label names
]);To sort by the .name I can ascend with a case-insensitive value for label.name:
const sortLabels = sortWith<Label>([
ascend((label) => label.type === LabelType.AutoLabel ? -1 : 1,
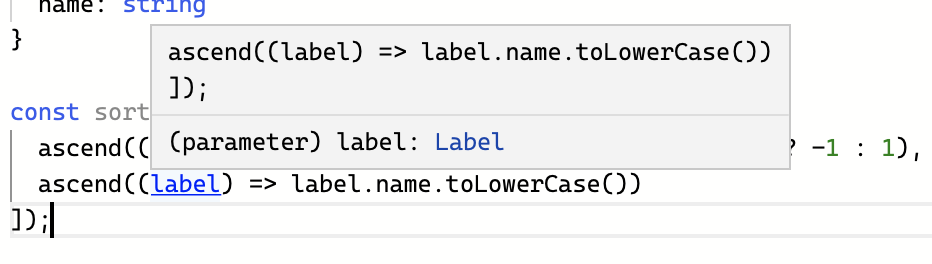
ascend((label) => label.name.toLowercase(),
]);Ramda is a curried API. This means by leaving out the second argument, sortLabels now has the TypeScript signature of:
type LabelSort = (labels: Label[]) => Label[]Since we hinted the generic type on sortWith<Label>() TypeScript has also inferred that the functions we give to ascend receive a Label type as their single argument (see on TS Playground).
Label as the inferred type.Given Ramda’s curried interface, we can extract that sorting business logic into a reusable constant.
/**
* Sort a list of Labels such that
* - AutoLabels appear before UserDefined
* - Labels are sorted by name case-insensitively
*/
export const sortLabelsByTypeAndName = sortWith<Label>(
[
ascend((label) => label.type === LabelType.AutoLabel ? -1 : 1,
ascend((label) => label.name.toLowercase(),
]
);Using this to replace the original code’s sorting we now have:
const filteredLabels =
data.community.labels.filter((label) => {
if (label.type === LabelType.AutoLabel &&
(isGroupPage === true ?
['system_a', 'special'] :
['system_a']
).includes(label.name)
) {
return false;
}
if (label.type === LabelType.UserDefined &&
label.stats.timesUsed === 0) {
return false;
}
return true;
});
const sortedLabels = sortLabelsByTypeAndName(filteredLabels);
return sortedLabels((label) => <>{/* React UI */}</>);Now let’s see what Ramda’s filter can do for us.
filterRamda’s filter looks similar to Array.prototype.filter:
Filterable f => (a → Boolean) → f a → f aTakes a predicate and a
Filterable, and returns a new filterable of the same type containing the members of the given filterable which satisfy the given predicate. Filterable objects include plain objects or any object that has a filter method such asArray.
The first change will be conforming to this interface:
import { filter } from 'ramda';
const filteredLabels = filter<Label>((label) => {
// boolean logic here
}, data.community.labels);There are two if statements in our original filter code that both have early returns. This indicates there are two different conditions that we test for.
Label if.type is AutolLabel and.name is in a list of predefined label namesLabel if.type is UserDefined and.stats.count is zero (or fewer)To clear things up we can turn these into their own independent functions that capture the business logic they represent.
The AutoLabel scenario has one complication. The isGroup variable changes the behavior by changing the names the label is allowed to have.
In Lambda calculus this is called a free variable. We can solve this now by creating our own closure that accepts the string[] of names and returns the Label filter.
const isAutoLabelWithName = (names: string[]) =>
(label: Label) =>
label.type === LabelType.AutoLabel
&& names.include(label.name);Now isAutoLabelWithName can be used without needing to know anything about isGroupPage.
We can now use this with filter:
const filteredLabels = filter<Label>(
isAutoLabelWithName(
isGroupPage
? ['system_a', 'special']
: ['system_a'],
data.community.labels
);But there’s a problem here. In the original code, we wanted to remove the labels that evaluated to true. This is the opposite of that.
In set theory, this is called the complement. Ramda has a complement function for this exact purpose.
const filteredLabels = filter<Label>(
complement(
isAutoLabelWithName(
isGroupPage
? ['system_a', 'special']
: ['system_a']
),
data.community.labels
);The second condition is simpler given it uses no free variables.
const isUnusedUserDefinedLabel = (label: Label) =>
label.type === LabelType.UserDefined
&& label.stats.timesUsed <= 0;Similar to isAutoLabelWithName any Label that is true for isUnusedUserDefinedLabel should be removed from the list.
Since either being true should remove the Label from the collection, Ramda’s anyPass can combine the two conditions:
const filteredLabels = filter<Label>(
complement(
anyPass(
isAutoLabelWithName(
isGroupPage
? ['system_a', 'special']
: ['system_a'],
isUnusedUserDefinedLabel
)
),
data.community.labels
);Addressing the free variable this can be extracted into its own globally declared function that describes its purpose:
const filterLabelsForMenu = (isGroupPage: boolean) =>
filter<Label>(
complement(
anyPass(
isAutoLabelWithName(
isGroupPage
? ['system_a', 'special']
: ['system_a'],
isUnusedUserDefinedLabel
)
);The <LabelMenu> component cleans up to:
import { anyPass, ascend, complement, filter, sortWith } from 'ramda';
import { Label } from '../generated/graphql';
type Props = { isGroupPage: boolean };
const isAutoLabelWithName = (names: string[]) =>
(label: Label) =>
label.type === LabelType.AutoLabel
&& names.include(label.name);
const isUnusedUserDefinedLabel = (label: Label) =>
label.type === LabelType.UserDefined
&& label.stats.timesUsed <= 0;
const filterLabelsForMenu = (isGroupPage: boolean): (labels: Label[]) => Label[] =>
filter<Label>(
complement(
anyPass(
isAutoLabelWithName(
isGroupPage
? ['system_a', 'special']
: ['system_a'],
isUnusedUserDefinedLabel
)
);
export const sortLabelsByTypeAndName = sortWith<Label>(
[
ascend((label) => label.type === LabelType.AutoLabel ? -1 : 1),
ascend((label) => label.name.toLowercase()),
]
);
const LabelMenu = ({isGroupPage, labels: Label[]}: Props): JSX.Element =>
const filterForGroup = filterLabelsForMenu(isGroupPage);
const filteredLabels = filterForGroup(labels);
const sortedLabels = sortLabelsByTypeAndName(filteredLabels);
return (
<>{
sortedLabels.map((label) => <>{/* React UI */}</>)
}</>
);
};The example above is very close to what we ended up landing.
However, since I like to get a little too ridiculous with functional programming patterns I decided to take it a little further in my own time.
pipeThe <LabelMenu /> component has one more step that can be converted over to Ramda using map.
Ramda’s map is similar to Array.prototype.map but using Ramda’s curried, data-as-final-argument style of API.
const labelOptions = map<Label>(
(label) => <>{/* React UI */}</>
);
return <>{labelOptions(sortedLabels)}</>; labelOptions is now a function that takes a list of labels (Label[]) and returns a list of React nodes (JSX.Element[]).
The <LabelList /> component now has a very interesting implementation.
filterLabelsForMenu returns a function of type (labels: Label[]) => Label[]sortLabelByTypeAndName is a function of type (labels: Label[]) => Label[].labelOptions is a function of type (labels: Label[]) => JSX.Element[].The output of each of those functions is given as the input of the next.
Taking away all of the variable assignments this looks like:
const LabelMenu = ({isGroupPage, labels: Label[]}: Props): JSX.Element => {
const labelOptions = map(
(label) => <>{/* React UI */}</>,
sortLabelsByTypeAndName(
filterLabelsForMenu(isGroupPage)(
labels
)
)
);
return <>{labelOptions}</>;
};To understand how labelOptions becomes JSX.Element[] we are required to read from the innermost parentheses to the outermost.
filteredLabelsForMenu is applied with props.isGroupPageprops.labelssortLabelsByTypeAndNamemap(<></>)JSX.Element[]We can take advantage of Ramda’s pipe to express these operations in list form.
Performs left-to-right function composition. The first argument may have any arity; the remaining arguments must be unary.
We’re in luck, all of our functions are unary. We can line them up:
const LabelMenu = ({isGroupPage, labels}: Props) =>
const createLabelOptions = pipe(
filterLabelsForMenu(isGroupPage),
sortLabelsByTypeAndName,
map(label => <key={label.id}>{label.name}</>)
);
return <>{createLabelOptions(labels)}</>
}The application of pipe assigned to createLabelOptions produces a function with the type signature:
type createLabelOptions: (labels: Label[]) => JSX.Element[];React’s functional components are also plain functions. Ramda can use those too!
The type signature of <LabelMenu /> is:
type LabelMenu = ({isGroupPage: boolean, labels: Label[]}) => JSX.Element;We can update our pipe to wrap the list in a single element as its final operation:
export const LabelMenu = ({isGroupPage, labels}: Props): JSX.Element => {
const createLabelOptions = pipe(
filterLabelsForMenu(isGroupPage),
sortLabelsByTypeAndName,
map(label =>
<li key={label.id}>
{label.name}
</li>
),
(elements): JSX.Element =>
<ul>{elements}</ul>
);
return createLabelOptions(labels);
}The type signature of our pipe application (createLabelOptions) is now:
const createLabelOptions: (x: Label[]) => JSX.ElementWait a second, that looks very close to a React.VFC compatible signature.
Our pipe expects input of a single argument of Label[]. But what if we changed it to accept an instance of Props?
export const LabelMenu = (props: Props): JSX.Element => {
const createLabelOptions = pipe(
(props: Props) =>
filterLabelsForMenu(props.isGroupPage)(props.labels),
sortLabelsByTypeAndName,
map((label: Label) =>
<li key={label.id}>{label.name}</li>
),
(elements): JSX.Element =>
<ul>{elements}</ul>
);
return createLabelOptions(props);
}Now the type signature of createLabelOptions is:
const createLabelOptions: (x: Props) => JSX.ElementSo if our application of Ramda’s pipe produces the exact signature of our a React.FunctionComponent then it stands to reason we can get rid of the function body completely:
type Props = { isGroupPage: boolean, labels: Label[] };
export const LabelMenu: React.VFC<Props> = pipe(
(props: Props) =>
filterLabelsForMenu(props.isGroupPage)(props.labels),
sortLabelsByTypeAndName,
map(label => <li key={label.id}>{label.name}</li>),
(elements) => <ul>{elements}</ul>
);The ergonomics of code like this is debatable. I personally like it for my own projects. I find the more I think and write in terms of data pipelines the clearer tho code becomes.
Here’s an interesting problem. What happens if we need to use a React hook in a component like this? We’ll need a valid place to call something like React.useState() which means we’ll need to create a closure for component implementation.
This makes sense though! A functionally pure component like this is not able to have side-effects. React hooks are side-effects.
The <LabelMenu /> component has a type signature of
type Props = {isGroupPage: boolean, labels: Label []};
type LabelMenu = React.VFC<Props>It renders a list of the labels it is given while also sorting and filtering them due to some business logic.
We extracted much of this business logic into pure functions that encoded our business rules into plain functions that operated on our types.
When I use <LabelMenu /> I know that I must give it isGroupPage and labels props. The labels property seems pretty self-explanatory, but the isGroupPage doesn’t really make anything obvious about what it does.
I could go into the <LabelMenu /> code and discover that isGroupPage changes which LabelType.AutoLabel labels are displayed.
But what if I wanted another <LabelMenu /> that looked exactly the same but behaved slightly differently?
I could add some more props to <LabelMenu /> that changed how it internally filtered and sorted the labels I give it, but adding more property flags to its interface feels like the wrong kind of complexity.
How about disconnecting the labels from the filtering and sorting completely?
I’ll first simplify the <LabelMenu /> implementation:
type Props = { labels: Label[] };
const LabelMenu = (props: Props) => (
<ul>
{labels.map(
(label) => <li key={label.id}>{label.name}<li>
)}
<ul>
);This implementation should contain everything about how these elements should look and render every label it gets.
But what about our filtering and sorting logic?
We had a component with this type signature:
type Props = { isGroupPage: boolean, labels: Label[] };
type LabelMenu = React.VFC<Props>;Can we express the original component’s interface without changing <LabelMenu />‘s implementation?
If we can write a function that maps from one set of props to the other, then we should also be able to write a function that maps from one React component to the other.
First write the function that uses our original Props interface as its input, and then returns the new Props interface as its return value.
type LabelMenuProps = { labels: Label[] };
type FilterPageLabelMenuProps = {
isGroupPage: boolean,
labels: Label []
};
const propertiesForFilterPage = pipe(
(props: FilterPageLabelMenuProps) =>
filterLabelsForMenu(props.isGroupPage)(props.labels),
sortLabelsByTypeAndName,
(labels) = ({ labels })
);There’s our Ramda implementations again. We took out all of the React bits. It’s the same business logic but without the React element rendering. The only difference is instead of mapping the labels into JSX.Elements the labels are returned in the form of LabelMenuProps.
We’ve encoded our business logic into a function that maps from FilterPageLabelMenuProps to LabelMenuProps.
That means the output of propertiesForFilterPage can be used as the input to <LabelMenu />, which is itself a function that returns a JSX.Element.
Piping one function’s output into a compatible function’s input, that sounds familiar, doesn’t it?
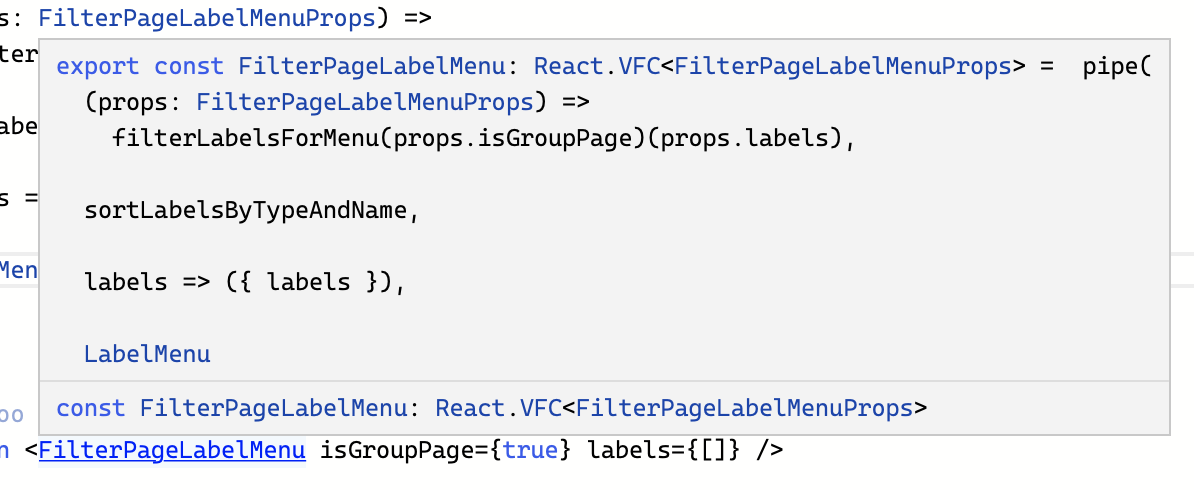
export const FilterPageMenuLabel: React.VFC<FilterPageLabelMenuProps> =
pipe(
(props: FilterPageLabelMenuProps) =>
filterLabelsForMenu(props.isGroupPage)(props.labels),
sortLabelsByTypeAndName,
(labels) = ({ labels }),
LabelMenu
);We’ve leveraged our existing view specific code, but changed its behavior at the Prop level.
import { FilterPageLabelMenuProps, LabelMenu } from './components/LabelMenu';
const Foo = () => {
const { data } = useQuery(query: LabelsQuery);
return (
<FilteredPageLabelMenuProps
isGroupPage={isGroupPage}
labels={data?.labels ?? []}
/>
);
}
const Bar = () => {
const { data } = useQuery(query: LabelsQuery);
return (
<LabelMenu labels={data?.labels ?? []} />
);
}
When hovering over the implementation of <FilteredPageLabelMenuProps> the tooltip shows exactly how it’s implemented:
Whenever I’m hiking I think of this talk by Feynman and it brings a sense of awe as I walk through the trees.
People look at trees and think it comes out of the ground … they come out of the air!
In a real-time chat workplace spelling and grammar tend to take a back seat to speed.
I typed qwerty proficiently for many years. After switching to Dvorak I have found that my fingers tend to translate the words I type phonetically.
I don’t know how to explain it. In my mind I’m using the word “their” but then I read back the sentence I just typed: “I don’t know there thoughts on …”. I’m always surprised. It’s not the word I had visualized but it’s the word I typed.
Sometimes I catch it but usually I hit enter before I read what I typed and quickly press up-arrow then e so I can quickly edit the grammatical error before too many coworkers have read it. (I just did it there. I know the word is “read” but my fingers type “red” and then I go back and fix it).
The scenario that always gives me problems is weather vs whether vs wether.
I think I always get “weather” right but my fingers never want to type an “h” after the “w”. They just aren’t used to that sequence of keys.
So I end up talking about castrated rams much more than I ever thought I would.